DirectX (Direct3D) のコンピュートシェーダー (Compute Shader, DirectCompute) には4バイト (uint) 単位で要素アクセスが可能なByteAddressBuffer/RWByteAddressBuffer (BAB) というデータ型があるんですが、DirectXにおいてGPUで頂点バッファの内容を直接変更しようと思ったらこのBABを使わざるをえません(もしくはジオメトリシェーダーとストリームアウトプットを使う方法もありますが)。CAPCOMもPC版ロストプラネット2のパーティクル実装にBABを使ってるらしいです。しかし正直BABはやたら使いづらく、StructuredBuffer/RWStructuredBuffer (SB) のほうが圧倒的に楽なんですが、GPUパーティクルを実装するのに技術的・性能的な比較検証を行なう上でしかたなく何かコード例がないか探していたら、CPUパーティクルとGPUパーティクルの速度比較検証結果を公開している記事を見つけました。
記事ではRadeon HD 5870のGPUパーティクルがCore i5(ごとき)のCPUパーティクルに負けたという結論になっているのですが、性能比較に使ったとかいう CPU (Intel Core i5) の型番が不明だし、そもそも公開されているオリジナルテストプログラム自体に謎のオレ様ライブラリが使われていて第三者がビルド・検証することすらできない半端な状態で、どうにも納得がいかない。おそらくGPU版のスコアが低かったとかいうのはRadeonが悪いんじゃない、そのオリジナルテストプログラムの設計がまずいのが原因だろうと思い*1、赤いきつねと緑のたぬきに代わって反証プログラムを書くことにしました。
オリジナルコードのまずい点
オリジナルコードはCPU版もGPU版もパーティクルの初期化(あるいは寿命が尽きたパーティクルの再初期化)をstd::rand()を使ってCPUで行なっています。GPUで書き換えることのできるリソース(RTV/UAVをバインドするリソース)はD3D11_USAGE_DEFAULTの指定が必須で、CPUで直接書き換えることはできないのですが、
- CPUで書き換えることのできるパーティクル1つ分の動的頂点バッファ(D3D11_USAGE_DYNAMIC)を用意しておく
- GPUで書き換えることのできるBAB頂点バッファの一部に対して上記をピンポイントにコピー転送することで初期化
- パーティクルの移動・回転といった更新のみをGPU(コンピュートシェーダー)で担当する
という手法を用いているようです。
これならば、すべてのGPUスレッドの仕事量が均一にはなるのですが、CPUの仕事が増えます。なによりGPUパーティクルなのに、初期化にCPUを使っているのがいただけない。
反証コードで改良した点
[1]
せっかくのGPUパーティクルなので初期化もすべてGPUにやらせてしまい、GPU側のみで完結させます。
プログラムではパーティクルの初速度 v0 と角速度 ω をランダムにするために乱数を使っているのですが、今回はGPUでも乱数を生成するために、std::rand()ではなくXorshift法を使った自前の乱数生成処理をC++とHLSLの両方で実装しました*2。
疑似乱数列を次々に生成していくためには「状態」およびその更新が必要となりますが、頂点バッファに乱数シードのフィールドを仕込んでおきます。
頂点バッファの1要素を表す構造体は下記のように定義します。簡単のため、一部DirectX Mathライブラリのデータ型を使っています。
struct MyVertexParticle2 final { XMFLOAT3 Position; XMFLOAT3 Velocity; float Angle; float DeltaAngle; float Size; XMUINT4 RandomSeed; };
RandomSeedフィールドに格納されている乱数をもとに生成した初速度・角速度を使ってパーティクルの初期化が完了したら、RandomSeedフィールドを新しい乱数で更新しておきます。
とはいえ、一番最初の乱数シードの状態生成までもGPU側でやろうとするとさすがに大変なので、最初の乱数だけは頂点バッファを生成するときにCPU側で全パーティクル分だけ計算しておきます。
[2]
オリジナルではコンピュートシェーダーのGPUスレッド1つで1つのパーティクルを処理させていましたが、スレッド1つに複数のパーティクルを処理させ、各スレッドの負荷を増やしてレイテンシを隠蔽し、ロードバランスをとります。また、ローカルグループサイズもオリジナルでは中途半端な100という数でしたが、Kernel Occupancyを最大化させる2のべき乗数を選びます。今回、各パーティクルの挙動は完全に互いに独立していて、グループ共有メモリを使うことがないため、ローカルグループサイズを調整してもあまり性能に大きく響いてこないようですが、コンピュートシェーダーを書くときは普段からNVIDIA WARPやAMD WAVEFRONTを意識してコーディングしたほうがよいでしょう。
#define MY_CS_LOCAL_GROUP_SIZE (256) #define MY_CS_PARTICLES_NUM_PER_THREAD (4)
#include "MyConstBuffers.hlsli" #include "MyVertexTypes.hlsli" #include "RandomNumHelper.hlsli" #include "CommonDefs.hlsli" RWByteAddressBuffer UavParticleBuffer : register(u0); #define SIZEOF_FLOAT (4) // cf. VSInputParticle2. #define VERTEX_ELEM_SIZE (SIZEOF_FLOAT * 13) #define POSITION_OFFSET (SIZEOF_FLOAT * 0) #define VELOCITY_OFFSET (SIZEOF_FLOAT * 3) #define ANGLE_OFFSET (SIZEOF_FLOAT * 6) #define DANGLE_OFFSET (SIZEOF_FLOAT * 7) #define PSIZE_OFFSET (SIZEOF_FLOAT * 8) #define RANDOM_OFFSET (SIZEOF_FLOAT * 9) void ResetParticle(uint globalIndex) { const uint vbBaseOffset = globalIndex * VERTEX_ELEM_SIZE; const uint4 random0 = UavParticleBuffer.Load4(vbBaseOffset + RANDOM_OFFSET); const uint4 random1 = Xorshift128Random::CreateNext(random0); const uint4 random2 = Xorshift128Random::CreateNext(random1); const uint4 random3 = Xorshift128Random::CreateNext(random2); const uint4 random4 = Xorshift128Random::CreateNext(random3); float3 position = float3(0,0,0); float3 velocity = UniMaxParticleVelocity * float3( Xorshift128Random::GetRandomComponentSF(random0), Xorshift128Random::GetRandomComponentUF(random1), Xorshift128Random::GetRandomComponentSF(random2)); float angle = 0; const float deltaAngle = UniMaxAngularVelocity * Xorshift128Random::GetRandomComponentSF(random3); position += velocity; velocity.y -= UniGravity; angle += deltaAngle; UavParticleBuffer.Store3(vbBaseOffset + POSITION_OFFSET, asuint(position)); UavParticleBuffer.Store3(vbBaseOffset + VELOCITY_OFFSET, asuint(velocity)); UavParticleBuffer.Store(vbBaseOffset + ANGLE_OFFSET, asuint(angle)); UavParticleBuffer.Store(vbBaseOffset + DANGLE_OFFSET, asuint(deltaAngle)); UavParticleBuffer.Store(vbBaseOffset + PSIZE_OFFSET, asuint(UniParticleInitSize)); UavParticleBuffer.Store4(vbBaseOffset + RANDOM_OFFSET, random4); // This random number will be used on next initialization. } void UpdateParticle(uint globalIndex) { const uint vbBaseOffset = globalIndex * VERTEX_ELEM_SIZE; float3 position = asfloat(UavParticleBuffer.Load3(vbBaseOffset + POSITION_OFFSET)); float3 velocity = asfloat(UavParticleBuffer.Load3(vbBaseOffset + VELOCITY_OFFSET)); float angle = asfloat(UavParticleBuffer.Load(vbBaseOffset + ANGLE_OFFSET)); const float deltaAngle = asfloat(UavParticleBuffer.Load(vbBaseOffset + DANGLE_OFFSET)); position += velocity; velocity.y -= UniGravity; angle += deltaAngle; UavParticleBuffer.Store3(vbBaseOffset + POSITION_OFFSET, asuint(position)); UavParticleBuffer.Store3(vbBaseOffset + VELOCITY_OFFSET, asuint(velocity)); UavParticleBuffer.Store(vbBaseOffset + ANGLE_OFFSET, asuint(angle)); UavParticleBuffer.Store(vbBaseOffset + PSIZE_OFFSET, asuint(UniParticleInitSize)); // The original program stored delta-angle instead of angle (Maybe just a bug) } [numthreads(MY_CS_LOCAL_GROUP_SIZE, 1, 1)] void main(uint3 did : SV_DispatchThreadID) { [unroll] for (uint i = 0; i < MY_CS_PARTICLES_NUM_PER_THREAD; ++i) { const uint globalIndex = MY_CS_PARTICLES_NUM_PER_THREAD * did.x + i; if (globalIndex == UniSpawnTargetParticleIndex) { // Reset the particle. ResetParticle(globalIndex); } else if (globalIndex < UniMaxParticleCount) { // Update the particle. UpdateParticle(globalIndex); } } }
あとコメントしてますがオリジナルのコンピュートシェーダーコードにはバグがありました……
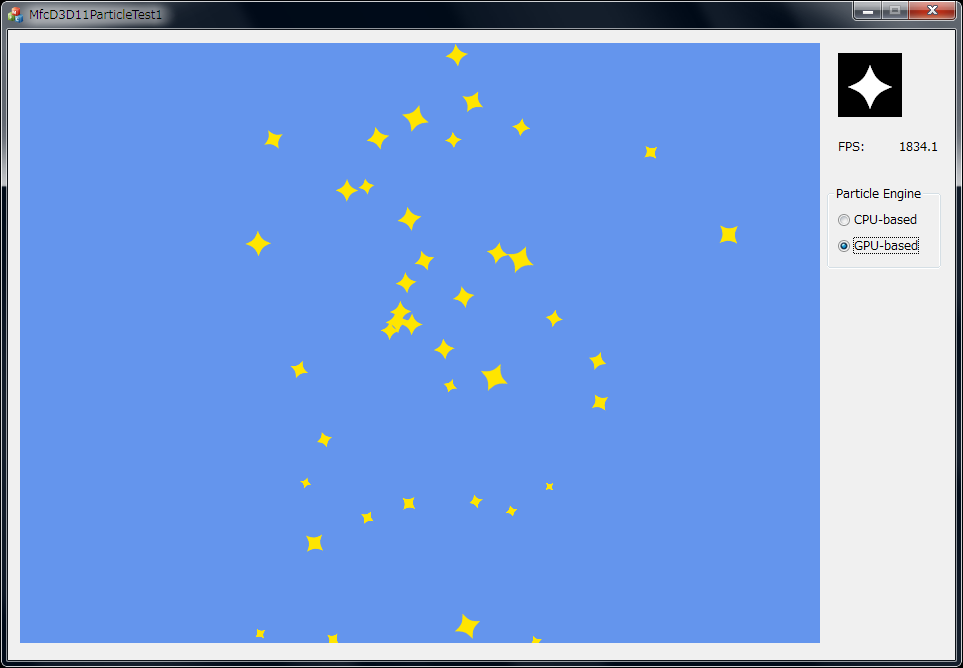
結果
結果はどうなったのか、Visual Studio 2012のProfessionalエディション以上を持ってる人は反証プログラムをビルドして試してみてください。実行にはDirectX 11.0(シェーダーモデル5.0)にフル対応したグラフィックスカードが必要になります。
今回はGUIにMFCを使っているため、Expressエディションとかいう貧弱な環境ではビルドできませんのであしからず。自分はWindows FormsもManaged DirectXもXNAも早期に見限りましたが、MFCは意外にまだまだ使えます。メンテナンスモードに限りなく近い枯れたフレームワークライブラリで欠点もありますが、Windows C++プログラマーであれば今からでも修得しておいて損はしないでしょう。あとGDIも今更感が強いですが、WPFを使うときとかも結局GDIを知っておいたほうが良いのでこれも損はしないでしょう。
ちなみにWin32高分解能パフォーマンスカウンターのほかにID3D11Queryを使った処理時間計測方法がありますが、環境によってはCPUパーティクルは一定時間経過後にフレームレートの数値が極端に落ち込むことがあるようです。なお自分の出した結論としては、「ハードウェアによる」が妥当なところだと思われます。ハイエンドのCore i7-4770KとミッドハイのGeForce GTX 760の組み合わせ(記事を書いている時点での市場価格はほぼ同一価格帯ですが)でネイティブ64bit版コードを試してみたところ、CPU版のほうが2倍近く高速でした。GPUの優位性を証明するとか息巻いていたわりには残念な結果になってしまい申し訳ないかぎりですが、GPUへのオフロードというのはCPUと速度比較するというよりはむしろ、適材適所というかCPUの負担を減らして余った時間でCPUにもっと複雑な別の仕事をやってもらうというのが最大の目的だと思います(小並感)。
あとはパーティクル同士の衝突とかやり始めると、GPUパーティクルというかGPUの並列処理優位性が効いてくるかもしれません。
もっと本格的なGPUパーティクル(特にパーティクル間の相互作用)をやりたい人は旧DirectX SDKサンプルのNBodyGravityCS11とか読みましょう。
また、Radeonに関しては、HD 7000シリーズ以降ではGPGPU性能を重視したGCNアーキテクチャが採用されているので、GPUパーティクルの性能も出やすくなっているかもしれません。
あと思ったんですが頂点バッファのほうはBABとかやめてスカスカにしてインスタンス描画をキックするためのダミーとし、実際のパーティクル状態は別の構造化バッファを用意して管理したほうがいいかもしれません。BAB使いにくすぎです。コードの見た目にも構造化バッファのほうがLoad/Store回数が減って高速な感じがします……
OpenGLではVBOをShader Storage Buffer Object(SSBO、構造化バッファ相当)としてバインドできることもあって、BAB相当機能が実装されてないようなのですが、やはりこれに関してはOpenGLのほうが正しい選択をしたんではないかと。DirectX 12のTyped UAV Loadではどうなるんでしょうか?
余談ですが件のオリジナルコードを書いた人は記事本文のテキストカラーやプログラムのパーツ各部にギトギトの原色を使う癖をなんとかしたほうが良いのではないかと思います。せっかくの文章も原色だと読みづらいし、またテストプログラムとはいえ、わざわざDirectX 11を使ってPC黎明期のゲームみたいな印象を受けるシーンをレンダリングするのはいかがなものかと。
ちなみに最近仕事でCUDAやOpenCLを使っているんですが、チューニングの知識はコンピュートシェーダーにもある程度通用するので、グラフィックスプログラマーであろうがなかろうがGPGPUに興味がある人はCUDAもOpenCLもやっておいて損はしないでしょう。